

“Una rosa, è una rosa, è una rosa” Gertrude Stein
La signora Stein intendeva dire che una rosa può essere un simbolo, ma alla fine è anche una rosa. E da qui potremmo dire che la capacità umana di astrarre è il fondamento di qualsiasi teoria, fra le quali rappresentare simbolicamente qualcosa: un dato.
Negli ultimi 30 anni la commistione fra informatica, insiemistica, teoria dei grafi, linguistica computazionale, data science e intelligenza artificiale hanno cambiato il mondo, cominciamo a parlarne a partire da concetti semplici.
Questa non è una pipa.
Come potete vedere nella foto di copertina dell’articolo anche Rene Magritte ha rappresentato artisticamente il fatto che un’immagine rappresenta qualcosa, ma non è la cosa.
Quindi, la nostra capacità di rappresentare nella nostra mente qualcosa a partire dalla sua immagine o dal suo nome, ci da accesso a infinite possibilità, idee e realizzazioni per la manipolazione della realtà, possibilmente per trarne un vantaggio.
I dati
Un Dato è un simbolo che può essere manipolato, ad esempio un numero può essere manipolato con il calcolo, oppure un Nome può essere declinato al plurale (Pipa, Pipe) o può essere un simbolo che rappresenta un’entità astratta come pi greco π o come infinito ♾️ .
SINGOLARE: Rosa – Rosae – Rosae – Rosam – Rosa – Rosa PLURALE: Rosae – Rosarum – Rosis – Rosas – Rosae – Rosis.
Quando i dati diventano più di uno se sono numeri possiamo manipolarli usando le tecniche dell’aritmetica possono essere contati, sommati, sottratti, moltiplicati, divisi. Usando le tecniche dell’insiemistica possiamo verificare se hanno qualcosa in comune categorizzandoli.
- Per poter essere rappresentati i dati hanno bisogno una struttura che li contenga.
- Per poter manipolare i dati noi umani dobbiamo conoscere i metodi che possiamo applicare, statistici ad esempio.
- Per poter estendere le tecniche di manipolazione dei dati dobbiamo definire le relazioni fra i dati, ad esempio la relazione fra un nome, un cognome e il numero di un documento di identità.
Se usiamo degli strumenti informatici come un foglio elettronico o un database possiamo organizzare la rappresentazione di qualcosa sotto forma di tabelle ed usare una serie di metodi propri dei software come Excel e Access, per citare i più popolari al momento, usati per contenere
per cercare, ordinare, e aggregare i dati.
I Database
Possiamo descrivere qualcosa con un testo, ad esempio un fiore così:
Questo fiore è una MARGHERITA, è di colore GIALLO ed è alta 15 cm.
Questo fiore è una VIOLA, è di colore VIOLA ed è alta 10 cm.
Questo fiore è un LILIUM , è di colore ROSSO ed è alta 110 cm.
Questo fiore è una ROSA , è di colore ROSSO ed è alta 90 cm.
Quindi ogni fiore ha delle qualità, che chiameremo attributi come :
- NOME
- COLORE
- DIMENSIONE
Se creiamo una tabella usando questi attributi otterremo:
Attributi=CAMPI
Righe=RECORD
| Nome | Colore | Dimensione |
|---|---|---|
| Margherita | Giallo | 15 |
| Viola | Viola | 10 |
| Lilium | Rosso | 110 |
| Tabella=DATABASE | ||
| Rosa | Rosso | 90 |
E’ possibile Inserire nuovi RECORD, modificarli, eliminarli, ordinarli, cercarli.
Come in un libro è possibile cercare le pagine dei fiori usando un INDICE.
In un database l’indice è un file separato e non visibile che contiene il numero di record, che è come un numero di pagina, ed il campo indicizzato, ad esempio il nome:
| Record | Nome |
|---|---|
| 3 | Lilium |
| 1 | Margherita |
| 4 | Rosa |
| 2 | Viola |
Però a differenza di un libro è possibile creare indici per ogni colonna, e molto rapidamente. Questo non si può fare con un elenco cartaceo.
Quindi se qualcuna arriva nel mio negozio di fioraio e mi chiede che fiori rossi ho, posso ordinare al volo la tabella sul database e rispondere.
L’informazione
“Di Dio ci fidiamo, gli altri portino i dati” – William Deming
L’informazione è una aggregazione di dati. Ad esempio, la somma dell’imponibile delle fatture ci dice il totale del fatturato, un nuovo dato derivato dall’aggregazione di altri dati.
Un record, composto da più campi è un’informazione.
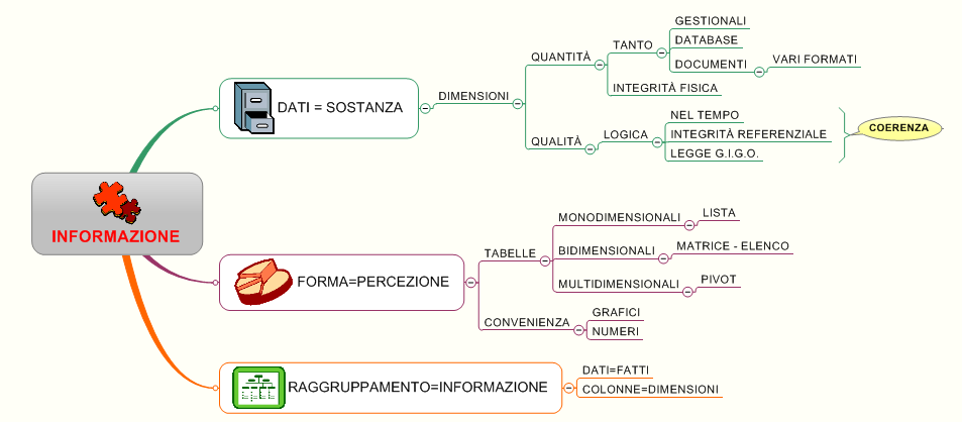
I dati vengono sempre visualizzati su una matrice di righe e di colonne, dove le colonne rappresentano la categoria o la proprietà di una informazione, il nome per esempio, mentre le righe rappresentano l’informazione grazie alla relazione fra le proprietà del singolo elemento, NOME, COLORE E DIMENSIONE.
Excel per manipolare i dati
Attualmente è possibile gestire una grande quantità di dati anche usando un foglio elettronico perché, nonostante utilizzi solo la memoria RAM del computer che lo ospita, può manipolare centinaia di migliaia di record in tempi accettabili. In Excel i database vengono chiamati elenchi.
Per fare qualsiasi operazione su un elenco è necessario avere il cursore posizionato al suo interno. Perché in un foglio Excel ci sono altre righe e colonne e quindi l’unico modo in cui Excel può sapere su cosa agire è verificare di essere in un rettangolo di dati, senza interruzioni sulla prima riga fra i nomi delle colonne e senza righe vuote. In questo modo è anche possibile avere più elenchi in aree diverse dello stesso foglio.
La gestione degli elenchi è quindi pensata per ottenere informazioni da un elenco:
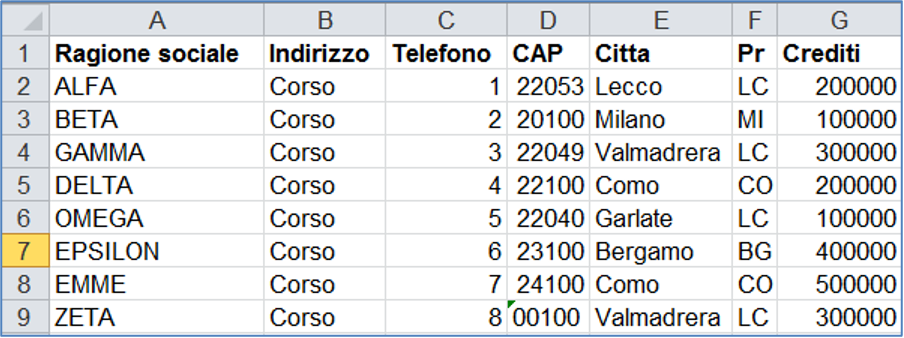
Per ottenere un’informazione da un elenco la prima cosa da fare è sempre ORDINARE, ad esempio per trovare il numero di telefono di un’azienda metterò in ordine di ragione sociale e sulla stessa riga troverò tutti i dati dell’azienda incluso il telefono.
L’ordinamento si fa sulle COLONNE, la lettura sulle RIGHE, in un database le colonne si chiamano CAMPI e le righe si chiamano RECORD.
Le colonne contengono tutte le caratteristiche dell’entità che possiamo descrivere con una frase, ad esempio:
“Il cliente ALFA che risiede in via CORSO a LECCO in provincia di LC con CAP 22053, numero di telefono 1 ci deve 200.000 euro” Ogni sinonimo ed aggettivo della frase possono diventare una colonna. In questo modo posso creare una tabella dove in ogni riga è rappresentata la sintesi della frase sopra esposta. Nella tabella è possibile aggiungere un grande numero di righe e quindi è comodo poter scegliere di ordinarle per una qualsiasi colonna.
Ad esempio, se voglio sapere chi è il cliente che mi deve più soldi il metodo più rapido è posizionare il cursore in una qualsiasi cella DENTRO la tabella nella colonna CREDITI e premere il pulsante di ordinamento decrescente che troviamo nel menù Dati .
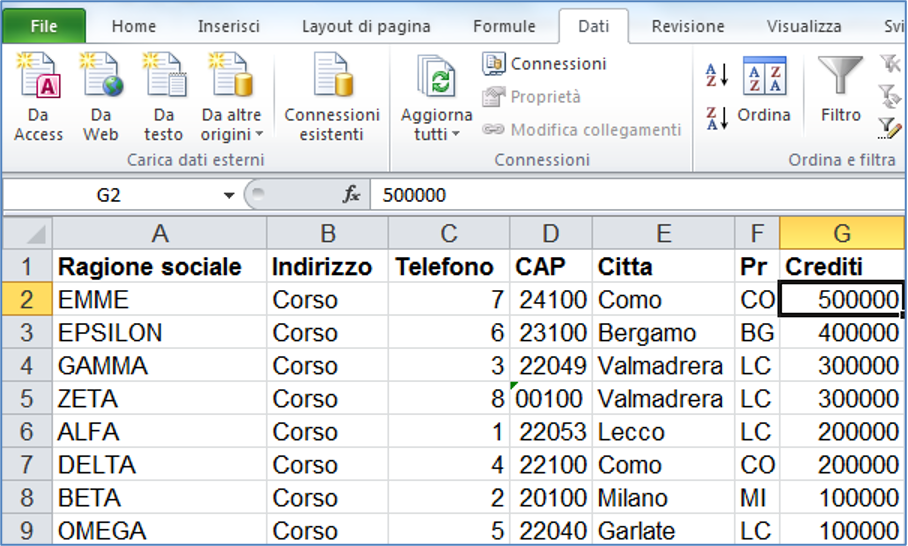
Notate che i sistemi di ordinamento che utilizziamo sono gli stessi che usiamo per scrivere, per contare e per orientarci nel tempo, ovvero l’ALFABETO, I NUMERI E LE DATE ed oltre a essere possibile ordinare per ogni singola colonna usando Excel l’ordinamento è molto più veloce che se fossero delle schede cartacee.
Ordinamenti
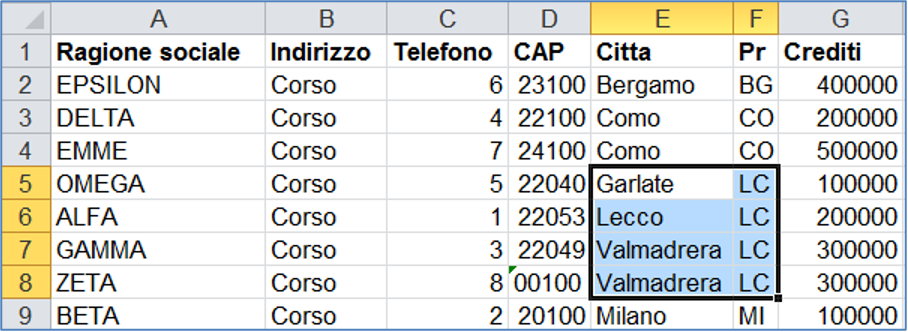
L’ordinamento di un elenco può anche essere più articolato, ad esempio posso avere bisogno di dare ai miei agenti il totale dei crediti che devono riscuotere, e visto che ho un agente per ogni provincia è comodo poter ordinare per PROVINCIA e, per aiutare l’agente, per CITTÀ. Lo posso fare a partire dal pulsante ordina che apre una finestra di dialogo nella quale posso inserire ordinamenti per livelli
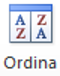

Il risultato:
Filtri
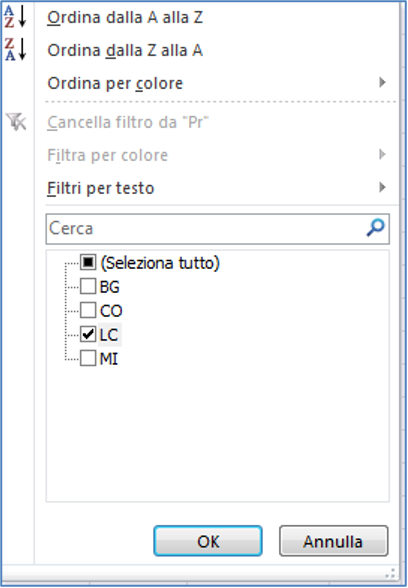
Dall’inizio degli anni ’90 è disponibile in Excel la funzionalità dei filtri, che permette di dichiarare cosa stiamo cercando con una modalità semplicissima. Per attivare questa modalità premiamo il pulsante FILTRO nel gruppo Struttura e la prima riga, contenente i nomi delle colonne dell’elenco, si trasforma in una serie di caselle combinate:


Se voglio vedere solo i clienti della provincia LC faccio clic sulla freccia nel lato destro della colonna Pr e mi apparirà una ricca finestra di dialogo che mi permette di vedere in ordine crescente i dati contenuti nella colonna provincia, senza ripetizioni e quindi di scegliere LC.
È anche possibile attivare e mantenere memorizzato un filtro attraverso una ricerca, cosa molto comoda se, ad esempio, voglio filtrare solo le descrizioni di un articolo che contengono una parola o parte di essa.
Il risultato:

In pratica Excel ha semplicemente nascosto le righe dove la colonna provincia non contiene LC, come possiamo vedere dai numeri delle righe a sinistra.
Per togliere il filtro attivato posso usare il pulsante Cancella, e per spegnere i filtri basta fare clic sul pulsante FILTRO che funziona come un interruttore acceso/spento.
Le relazioni
“Tutti i modelli sono sbagliati, ma alcuni sono utili” – George Box
Le relazioni derivano dalla comune appartenenza dei dati ad un qualche tipo di insieme o in qualche tipo di categoria. Ad esempio, un record è la relazione fra i campi che lo compongono per descrivere le proprietà, gli attributi di una entità come nella tabella delle aziende, dove ogni riga contiene i dati che ci servono per costruire delle informazioni significative.
I database più diffusi si basano sull’insiemistica e si chiamano per l’appunto database relazionali.
Se ad esempio ho una tabella che contiene i dati anagrafici dei clienti e ho una tabella che contiene l’elenco degli ordini che ricevo, la tabella degli ordini conterrà sicuramente una colonna con il codice identificativo del cliente. Il codice identificativo del cliente nasce della tabella dei clienti ed è univoco per ogni cliente. In questo modo io posso interrogare la tabella degli ordini cercando il codice di uno specifico cliente e vedere tutti i suoi ordini perché il codice del cliente crea una relazione con gli ordini.

I database hanno un linguaggio specializzato per interrogare i dati che si chiama S.Q.L. structured query language.
I grafi
La teoria dei grafi permette di visualizzare dei fenomeni che dipendono dal tipo di relazione fra i dati, ad esempio da sinistra verso destra abbiamo:
Identificazione delle comunità, centralità, previsione di collegamenti, somiglianza, ricerca del percorso più breve

Anche per i grafi sono stati creati strumenti informatici, che appartengono alla classe dei database e si chiamano GraphDB. Non esistono record, esistono solo nodi e relazioni. Sia i Nodi che le relazioni possono avere un record di dati che li descrive e ogni relazione deve avere una direzione.

I database grafici sono meno diffusi ma in rapida espansione perché sono molto efficienti nel manipolare grandi quantità dii dati e offrono un’alternativa più semplice alla programmazione pura per interrogare i dati. L’uso dei grafi è l’analisi delle associazioni fra i dati, ad esempio quando Amazon vi suggerisce i libri da leggere usa un grafo.
Statistica
Molti metodi statistici, come le correlazioni e le regressioni, sono basati sulla relazione fra colonne di dati della stessa tabella. Ad esempio, misurare la correlazione fra il prezzo degli immobili e la posizione rispetto al centro della città vuol dire verificare quanto è probabile che un immobile abbia un valore più alto quando è in una posizione più vicina al centro della città.
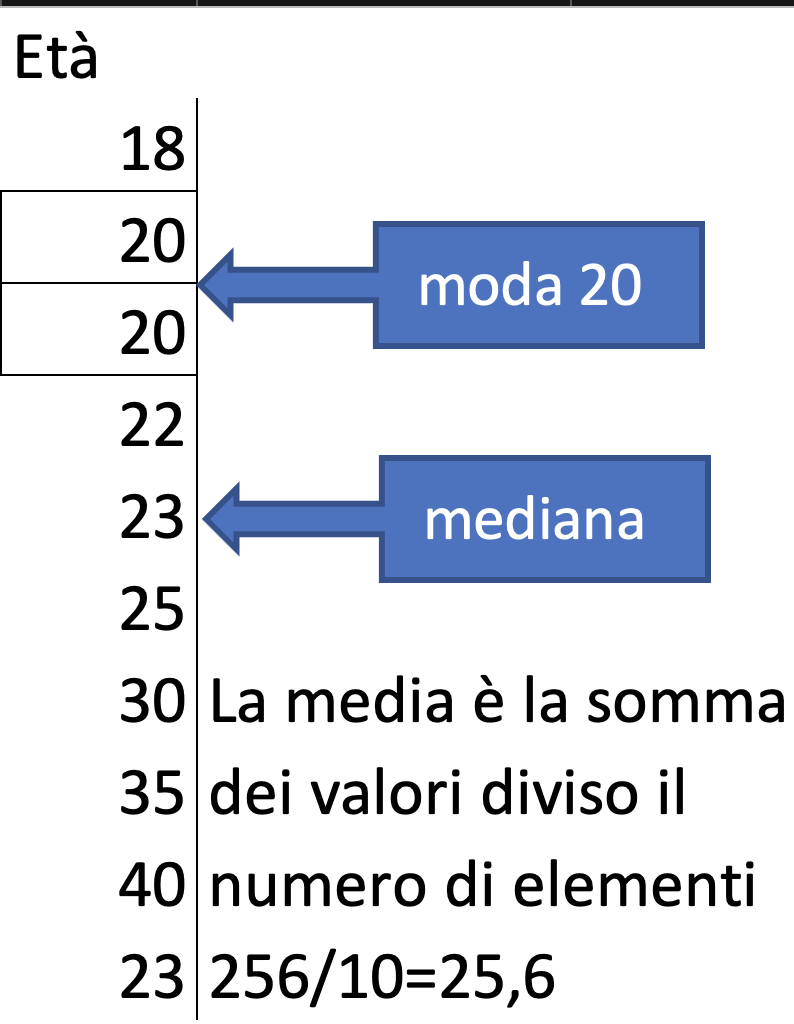
Altri metodi come la moda, la mediana e la media sono basati sulle relazioni fra i dati di una colonna o di una riga.
Nel master Lecco 100 incappiamo spesso in problemi di rappresentazione grafica, di linguistica e in fenomeni numerici, ad esempio relativamente ad internet, all’intelligenza artificiale o alle block-chain.
Questo post è solo la punta dell’iceberg e lo’ho scritto perché da qualche parte bisogna cominciare. La buona notizia è che è possibile creare dei modelli per ogni cosa si voglia rappresentare, la cattiva notizia è che c’è sempre una percentuale di errore.
Vuoi partecipare al master nel 2023?
come iscriversi: https://www.lecco100.it/index.php/2022/09/08/vuoi-partecipare-al-master-2023/
il programma: https://www.lecco100.it/index.php/2022/09/07/stiamo-progettando-il-master-del-2023